통계, ML 방법론
[혼공머] 6장 비지도학습
eun_00
2024. 9. 24. 21:31
출처: [혼자 공부하는 머신러닝+딥러닝] 책
💡 타깃이 없는 데이터를 사용하는 비지도 학습과 대표적 알고리즘을 알아보자 (K-평균, PCA)
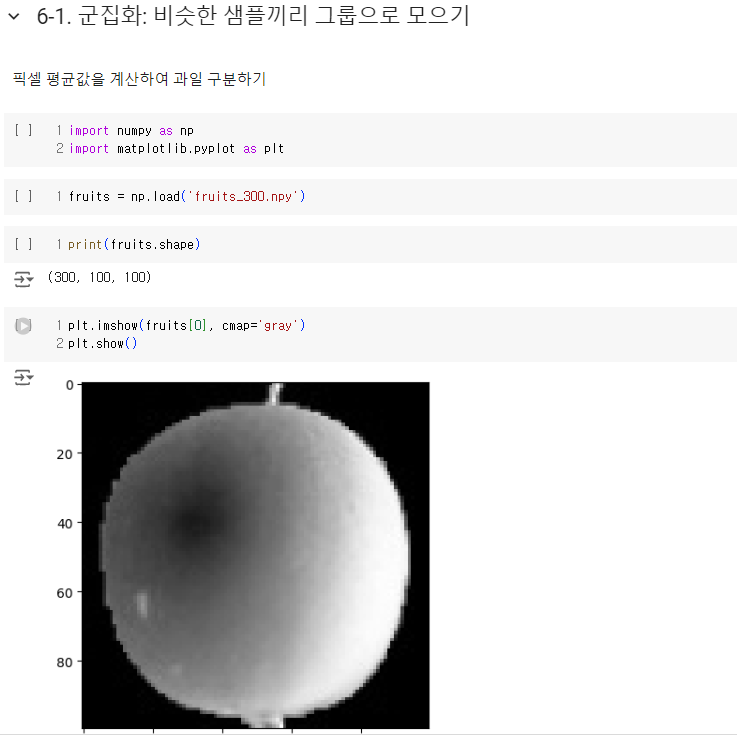
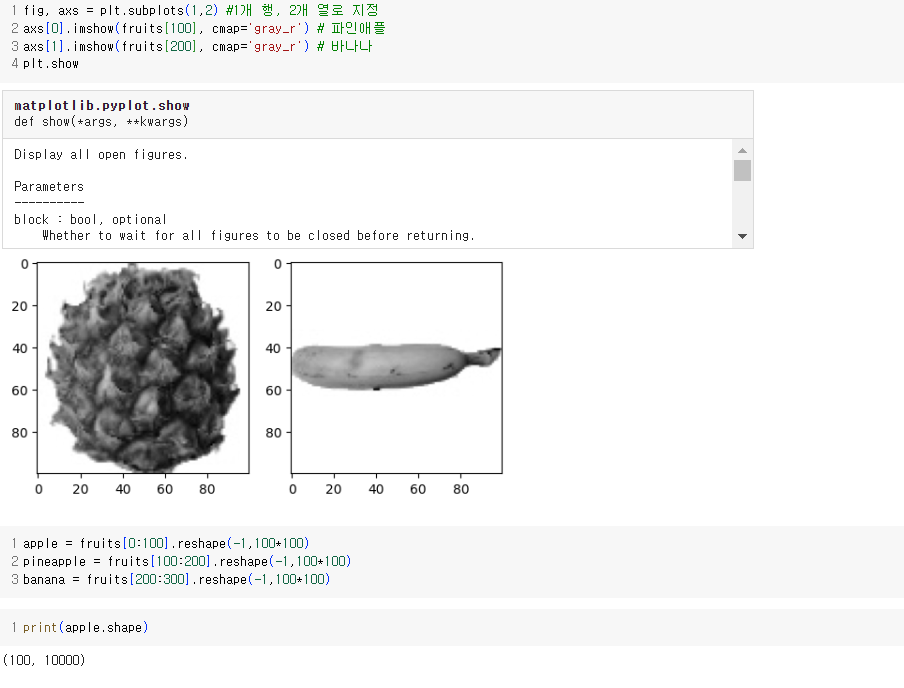
- 바나나는 픽셀값으로 확실히 구분되지만 사과와 파인애플은 대체로 동그랗고 사진에서 차지하는 크기가 비슷하기 때문에 픽셀값이 많이 겹친다.
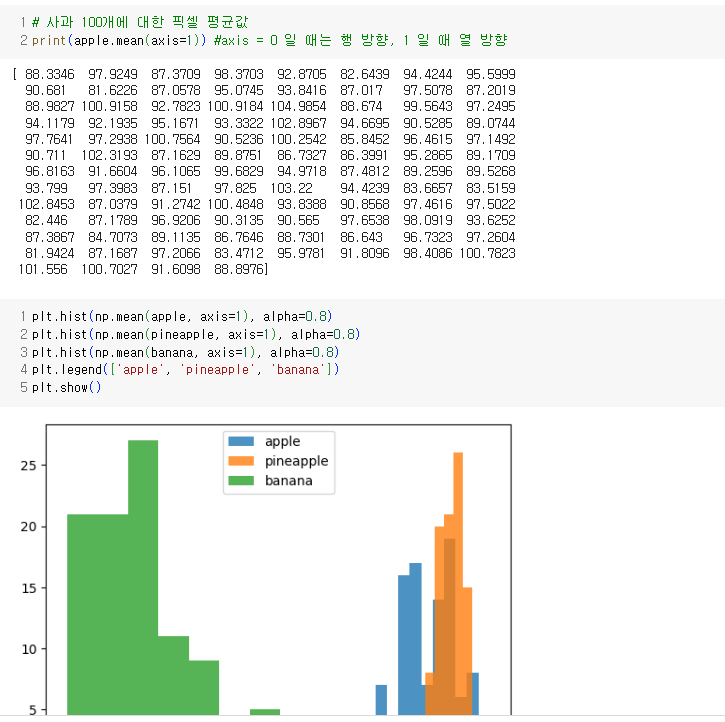
- 전체 샘플에 대한 각 픽셀의 평균을 계산하기 위해 axis = 0으로 지정하여 평균값 막대그래프를 만든다.
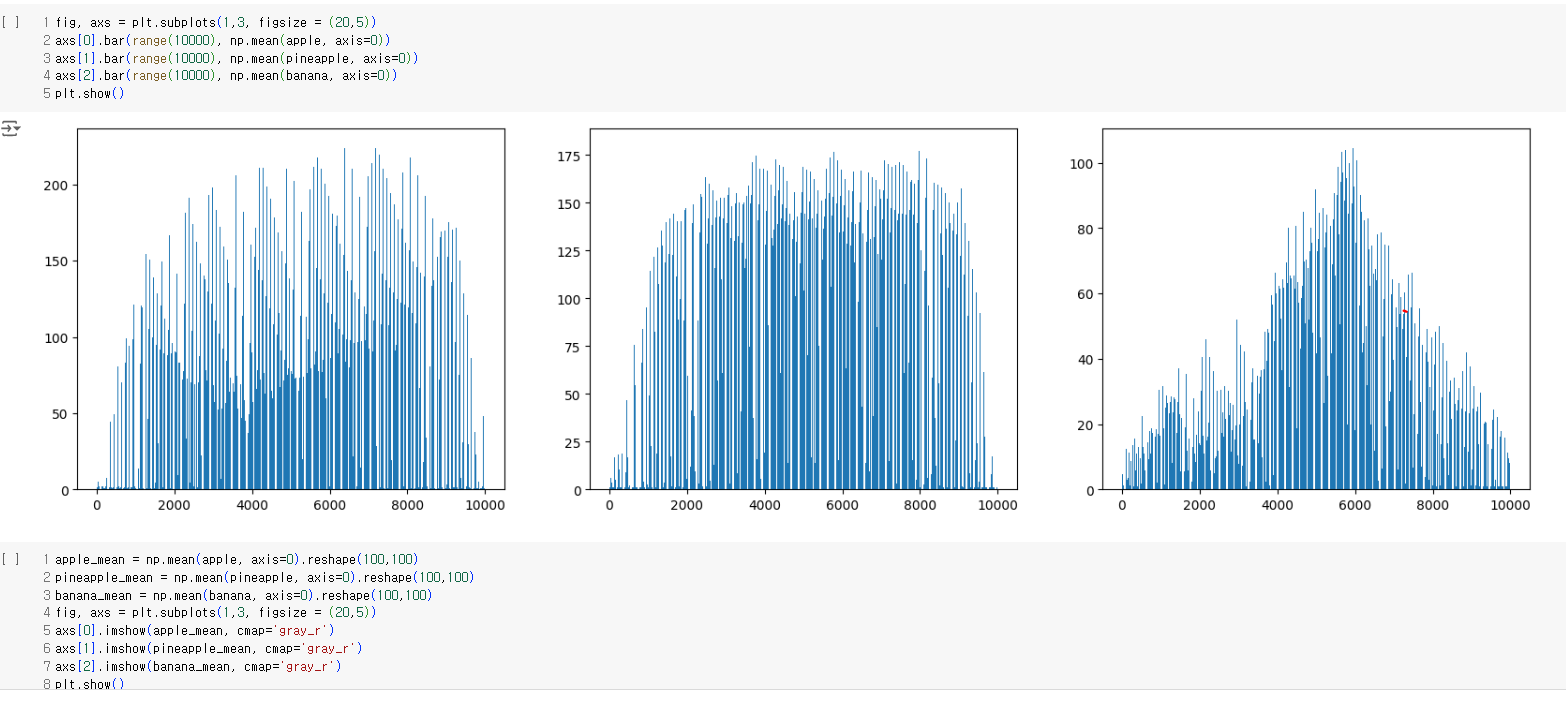
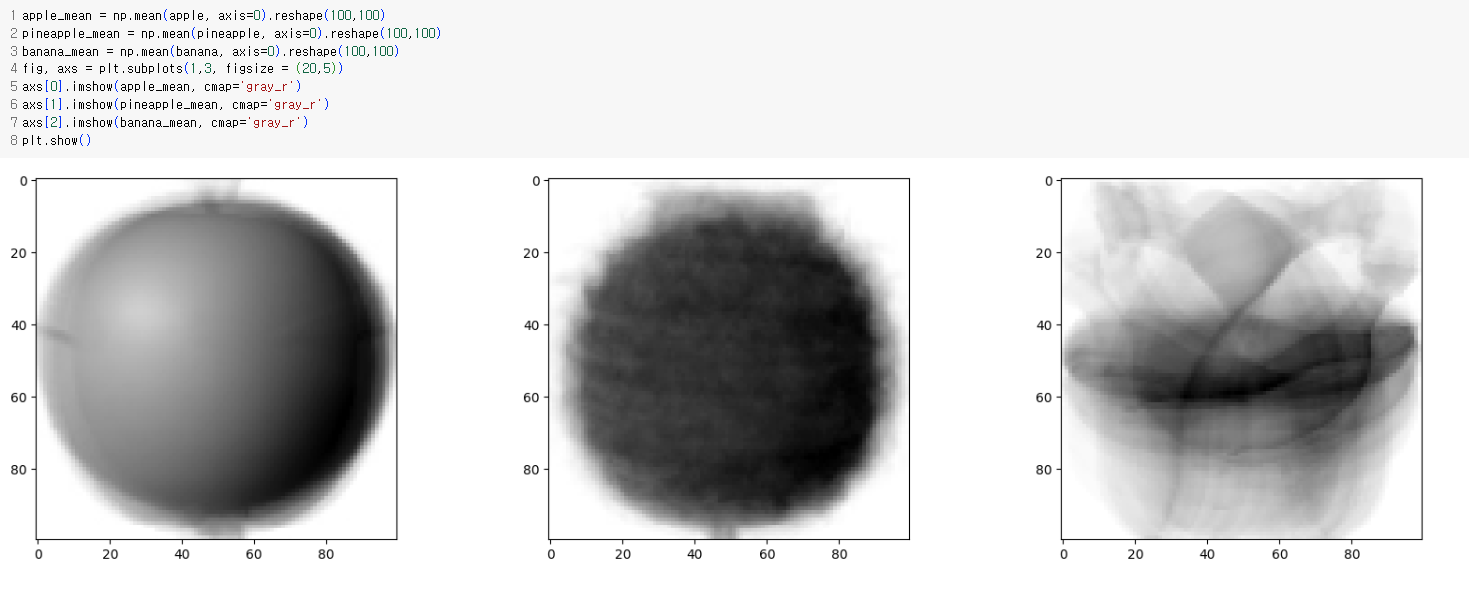
각 과일은 픽셀 위치에 따라 값의 크기가 차이난다.
평균값과 가까운 사진 고르기
- fruits 배열에 있는 모든 샘플에서 apple_mean을 뺀 절댓값의 평균을 계산한다.
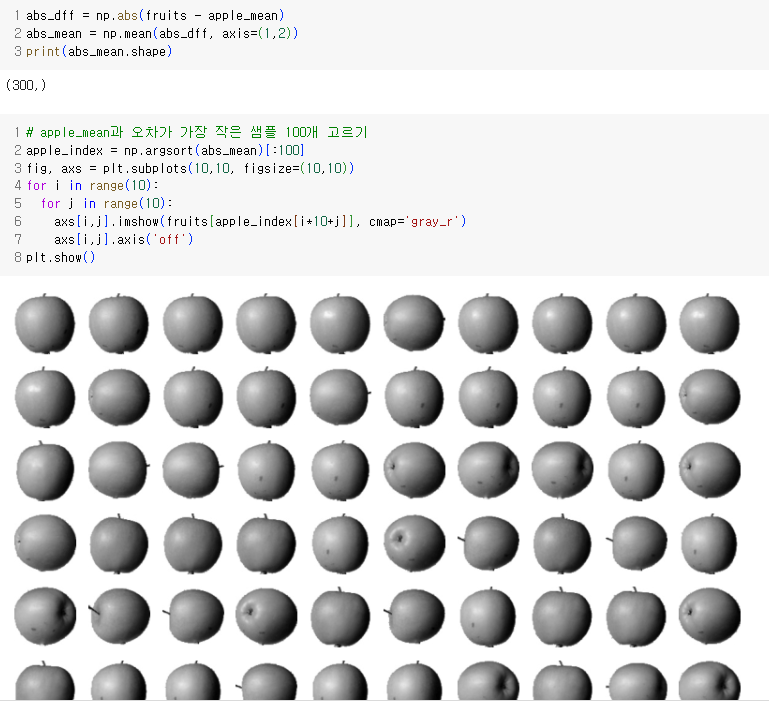
apple_mean과 가장 가까운 사진 100개가 모두 사과임을 알 수 있다.
- 비슷한 샘플끼리 그룹으로 모으는 작업을 군집 clustering 이라고 한다. 군집 알고리즘으로 모은 샘플 그룹을 클러스터 라고 한다.
- 사과, 파인애플 등 이렇게 타깃값을 알고 있는 경우는 평균값을 구할 수 있지만 타깃값을 모르는 경우 평균값을 계산할 수 없다. 이 경우 해결하기 위해서 k-평균 알고리즘이 있다.
히스토그램은 구간별로 값이 발생한 빈도를 그래프로 표시한 것이다. 보통 x축이 값의 구간, y축이 발생 빈도이다.
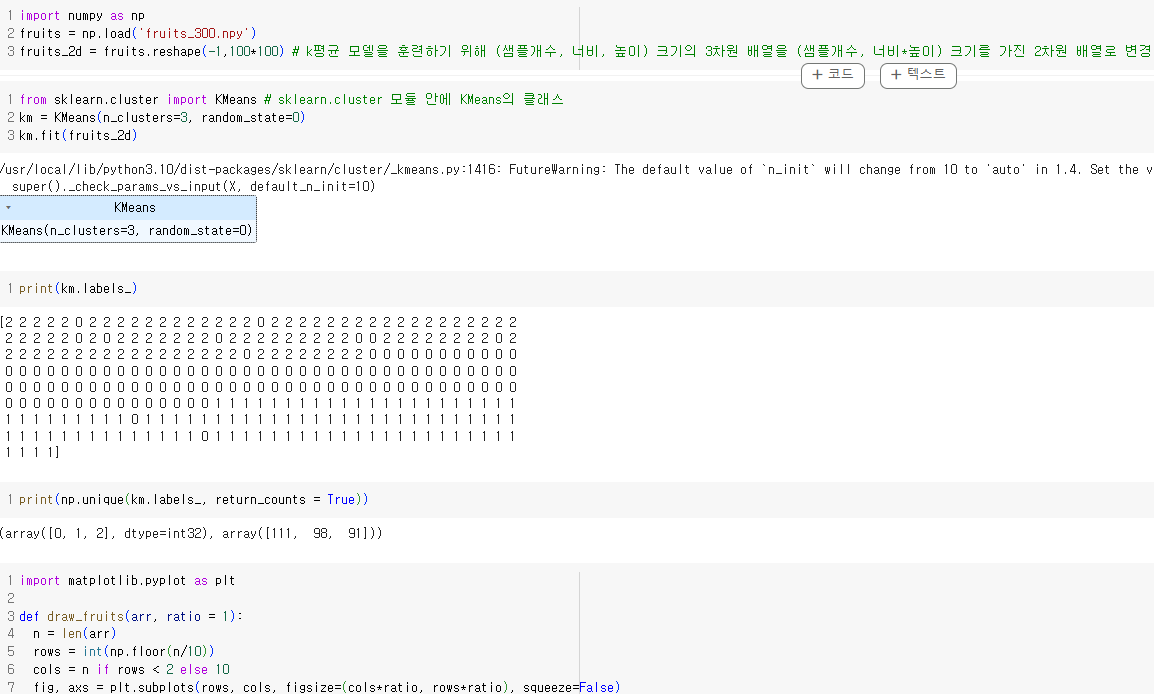

- k-평균 알고리즘은 처음에 랜덤하게 클러스터 중심을 정하고, 클러스터를 만든다. 그 다음 클러스터의 중심을 이동하고 다시 클러스터를 만드는 식으로 반복해서, 최적의 클러스터를 구성하는 알고리즘이다.
- 클러스터 중심은 k-평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값이다. 가장 가까운 클러스터 중심을 샘플의 또 다른 특성으로 사용하거나 샘플에 대한 예측으로 활용할 수 있다.
- Kmeans 알고리즘은 클러스터 개수를 사전에 미리 지정해야하는데, 엘보우 방식은 최적의 클러스터 개수를 정하는 방법 중 하나이다.
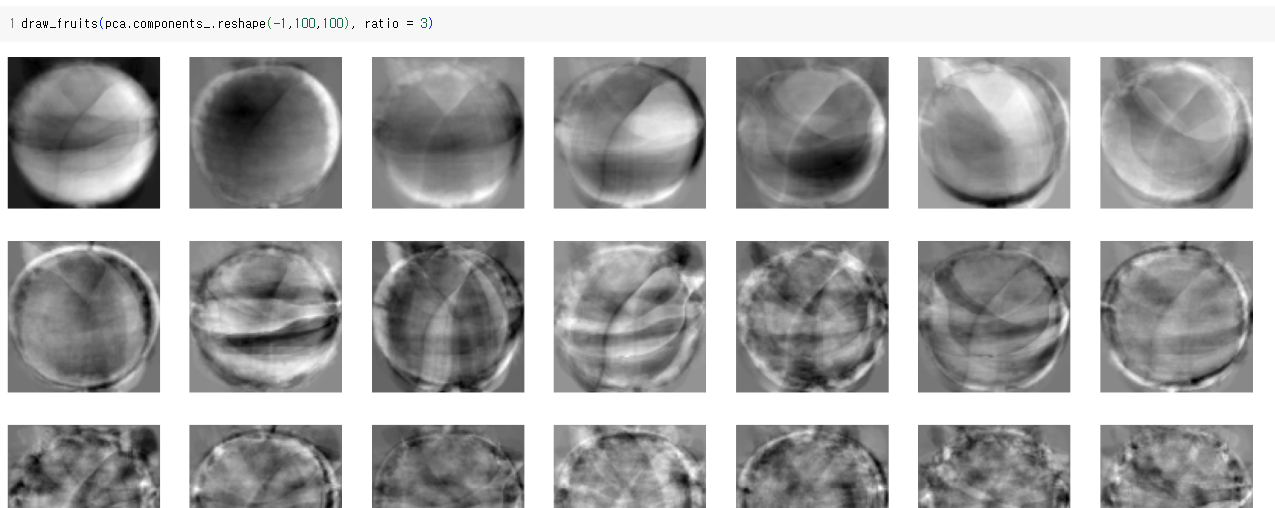

50개의 주성분을 찾은 PCA 모델을 사용해 이를 (300, 50) 크기의 배열로 변환하였다.
- 주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값을 설명된 분산이라고 한다.
💡 PCA 활용하여 로지스틱 회귀모델 만들기

50개의 특성만 사용했을 떄 정확도 100%와 훈련시간이 이전에 비해 약 20배 이상 감소함을 알 수 있다.
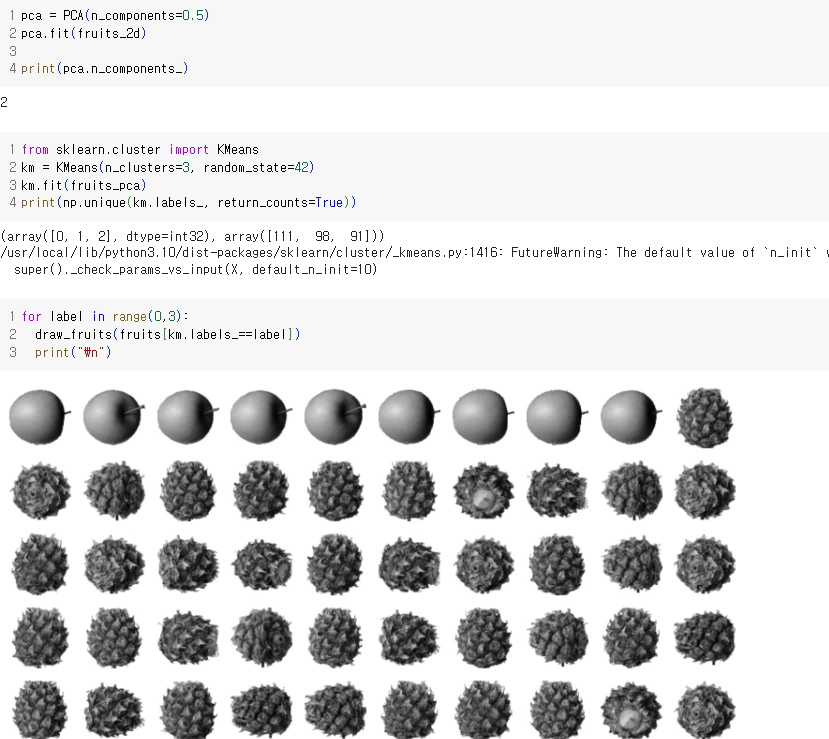
훈련데이터 차원을 줄이면 시각화하기 쉽다. fruits_pca는 2개 특성으로 되어 있어 2차원으로 표현할 수 있다.
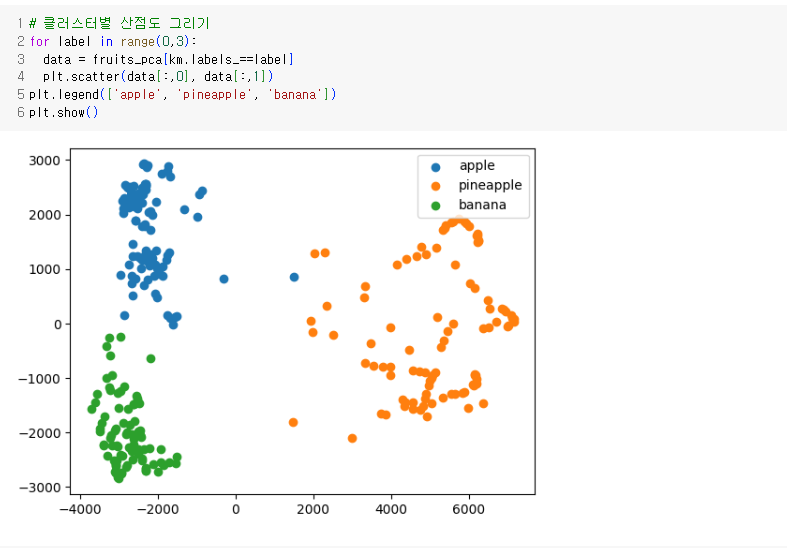
- 차원 축소 시 시각화하기 쉽고 알고리즘 성능을 높일 수 있다.
- 주성분 분석은 차원축소 알고리즘 중 하나로 가장 분산이 큰 방향을 찾는다.
💡 비지도학습 실생활 활용 분야
- 고객 세분화: 고객을 여러 그룹으로 나누고 각 고객 행동 선호도 구매력 분석
- 이상치 탐지: 일반적인 data 패턴을 파악하고 크게 벗어난 경우 이상치로 탐지
- 추천 시스템: 선호도 기반으로 사용자 그룹 형성하고, 같은 그룹 내 다른 사용자가 선호하는 항목을 추천